
Google’s core services are used by hundreds of millions of people, which makes testing the underlying code a Herculean task, to put things mildly. Over the years, Google has adapted to this challenge by iterating on how its engineers build and improve test infrastructure. As explained in a series of postings on
the Google Testing Blog, much of that evolution has necessarily taken place on a cultural level: without thousands of people thinking constantly about how to make the process more efficient, nothing can happen. A long time ago, Google also created three engineering “tracks”: test engineers, release engineers, and site reliability engineers. After a few more years, as testing became more automated, testing roles at the company split again, onto two tracks: test engineers (TEs), who tested software, and software engineers in test (SETs), who built frameworks required for automated testing. As a result of that latter split, “automated tests became more efficient and deterministic (e.g., by improving runtimes, eliminating sources of flakiness, etc.),” according to one of the Google Testing Blog postings. “Metrics driven engineering proliferated (e.g., improving code and feature coverage led to higher quality products).” Tools built by the SETs included automated release verification, automated measurements of developer activity, and extending IDEs to make “writing and reviewing code easier,” in the words of the blog. Another posting
delves into Google’s test infrastructure, and how the need to constantly refresh and improve massive legacy systems creates a need for new tools. It’s worth reading for the description of how a group of dedicated engineers took a “complex and brittle” legacy system and transformed it into something that could be easily maintained and extended. The key to that transition? Making small system tests more powerful. For example:
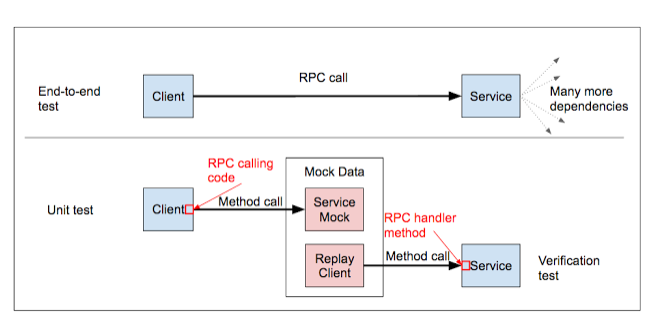
While most engineers probably won’t work on systems the size of Google’s during their careers, these postings are invaluable for a look at how best practices evolve in a cloud-engineering context. There are definitely lessons in here for anyone wrestling with a system of their own, no matter how big or small.


